With the current launch of v12 and the growing ecosystem of AuditAgent, I could no longer stay quiet. Throughout this post I will share some of my own results and opinions on the growing role AI plays in smart contract security going forward.
I strongly dislike what the current LLM hype has become for smart contract auditing. I am by no means against AI. This trend really started to bother me when the Pashov Solidity Auditor suite was released and went viral. Since then, with products like v12 opening up to everyone, the pace has only accelerated.
And the core issue, in my opinion, is this:
What is currently being implemented in many of these so called "AI scanners" is fundamentally wrong.
What is my problem?
It is not a small issue. It is a foundational one.
Back to first principles
Smart contracts are stateful programs. Their behavior depends on the state they are in at any given moment.
If you want to reason about a lending protocol, you cannot just read the code in isolation. You must account for the evolving state: balances, collateralization ratios, oracle values, liquidity, and more.
Many real vulnerabilities only emerge after sequences of actions:
- Deposit collateral
- Borrow against it
- Manipulate an oracle
- Trigger liquidation
These are not single function bugs. They are state transitions across time.
The Hype Problem
My second issue is that much of the current “innovation” in AI security tooling is driven by hype.
"7 AI audit skill files every xxx should know about!!"
This completely misses the point.
The industry is blurring the line between AI as a field and LLMs as a tool. What we call “AI auditors” today are, in practice, LLMs reading code, doing pattern matching, and producing static opinions based on plausible sounding outputs.
Yes, modern models can reason better. And with agentic systems, they can even research and iterate. But they still do not execute any transaction, explore state transitions, or prove exploitability.
They produce opinions.
And often, they confidently report “possible vulnerabilities” that may never exist in any real execution path.
Current state
To summarize, I think most public tools today can be reduced to something like this:
@claude pls find all vulns thx, no mistakes
That is not security engineering.
I do not want a report that sounds plausible. I do not want to spend any brainpower verifying whether something is real.
I want a guarantee that a reported issue is a real, reproducible bug. The future of vulnerability research is not scanning Solidity code and generating hypotheses.
My Nethermind Journey
I have always been fascinated by fuzzing, especially in blockchain systems.
After my time on the security team at Nethermind, I spent a lot of time thinking about how fuzzing could be properly integrated into audit workflows.
I worked briefly on the AuditAgent team. One of my main goals was to make fuzzing a part of the audit flow, to both find and verify vulnerabilities.
The ambition was there. But the execution and the surrounding architecture had problems in my opinion. I mean, it worked when I tested it towards audit contests running at that time.
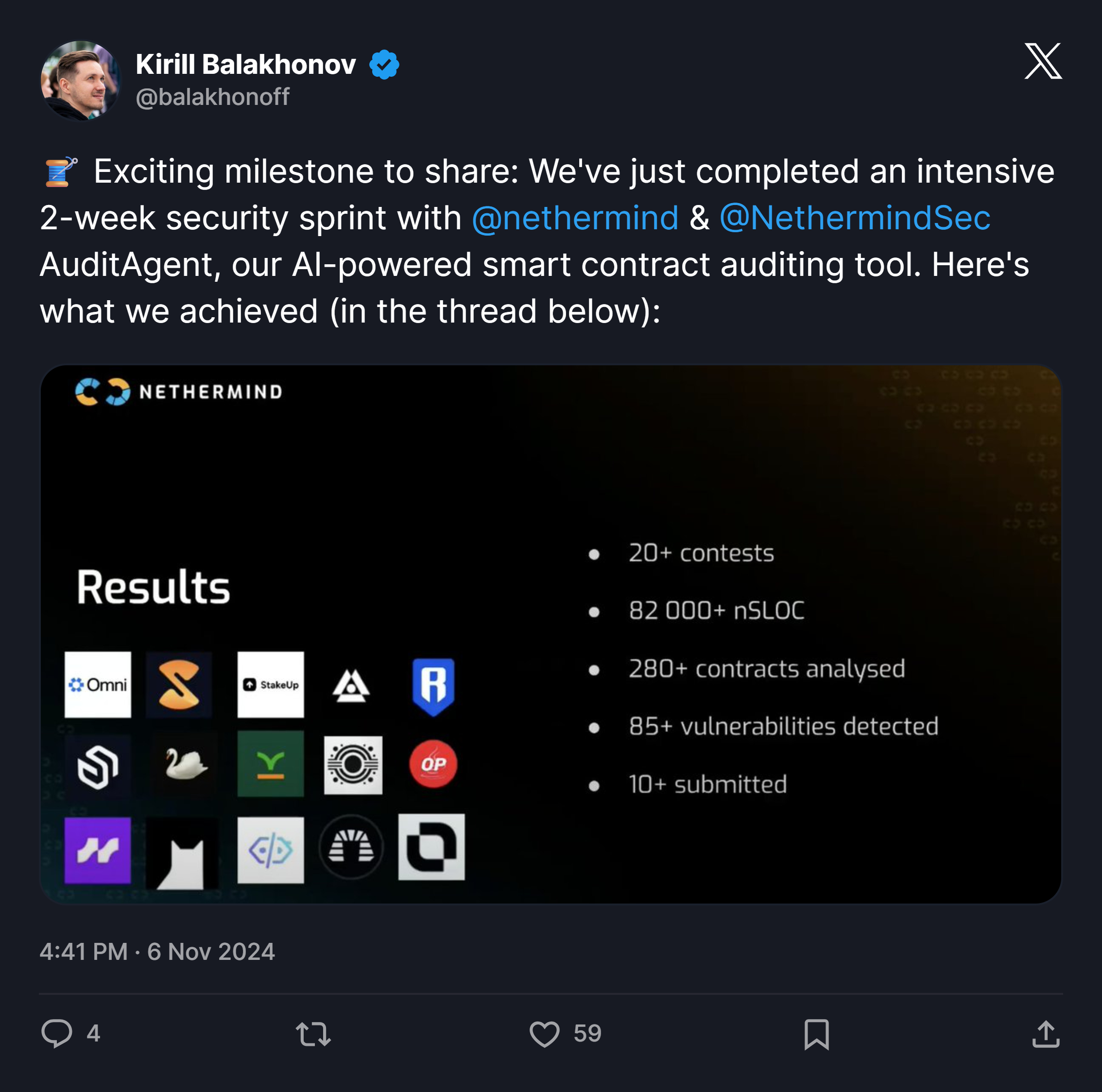
But what I kept running into was hallucination, missing simple bugs, and floods of plausible sounding output that required manual triage to sort through.
If a tool creates more work than it saves, it has failed.
So for the last several months, I tried to automate this properly.
Don't Trust, Verify
I really think we need to stop and take a few steps back to the core principle blockchains are built on, such as:
Don't Trust, Verify
Fuzzing aligns perfectly with it. It doesn't need to "understand" code.
It executes, mutates inputs, tracks coverage, and breaks invariants. The feedback loop is binary. An invariant either fails, or it doesn't.
No opinions. No hallucinations. And importantly:
Every real vulnerability is a 0-day until it is discovered.
How 0-Days Actually Get Found
A short sidenote on how real vulnerability research works, because I think the blockchain space has a lot to learn from the broader security community.
The reality of bug discovery
The most impactful vulnerabilities, heap overflows, use-after-frees, type confusions, are hard to find, especially in commercial grade software.
These programs are large and hardened, and exploiting them often requires chaining together a UAF with an OOB read and a buffer overflow to potentially achieve RCE. Bugs found purely by someone reading code and going "hmm, this looks suspicious" are rare.
The best way to hunt for 0-days at scale is to let a fuzzer hammer inputs until a pointer goes out of bounds, memory gets corrupted or a process crashes.
That crash is the truth. A broken invariant is the truth. Everything else is pure speculation.
This is why platforms like Code4rena and Immunefi require PoCs:
An unproven claim is not a vulnerability. It is a hypothesis.
That is exactly what I feel like is missing from these AI scanner products. They produce hypotheses and call them findings.
The Simulation Gap
This is the wall that LLMs cannot climb, regardless of how many parameters they have.
An LLM reads code the way a human reads code. It builds a mental model of what the code probably does, without ever executing it or interacting with it.
A fundamental flaw is that LLMs pattern match against known vulnerability classes, because that is what they were trained on. And as you can imagine, the training data does not contain vulnerabilities that have not been discovered yet.
An LLM produces a narrative about what might go wrong, based on prior training data. But projects are not alike, and they should be treated separately. Loading every known vulnerability class for a lending protocol into context when the target is a governance contract is wasted tokens and wasted focus, a "one size fits all" approach that is architecturally wasteful in my opinion.
The product might write a fancy report PDF in fluent English, confident, and be completely wrong, because the code path that actually triggers the imagined bug only materializes at transaction 47 in a specific sequence, with a specific oracle value, against a specific pool state.
An LLM cannot simulate that. It is reasoning about execution, which is fundamentally different from execution itself. Combining this with an agentic approach is interesting if you can sufficiently control the feedback loop, but the drift problem is real.
This is not a limitation that better prompting will fix. It is architectural.
I am against “AI triage” as a security workflow
One of the clearest signs that the industry is moving in the wrong direction is that it is now creating roles specifically around triaging AI-generated smart contract findings. Nethermind has advertised a role called:
“Web3 Security Triager”

This should not exist.
If your system requires humans to filter out hallucinations, it has already failed.
If your security pipeline depends on a human sitting there reviewing piles of slop generated vulnerability reports, the system has already failed at the most important level. That is not a breakthrough in security engineering. That is outsourcing hallucination cleanup to humans.
The goal should not be to generate as many plausible vulnerability claims as possible and then hire people to sort through them. The goal should be to produce findings that are already grounded in execution.
In smart contract security, for me, a finding should exist because it was demonstrated, reproduced, and validated by a deterministic system, not because an LLM produced a convincing explanation that now needs manual evaluation and manual demonstration.
This is exactly why I keep coming back to fuzzing.
A good system should give you one of two outcomes:
- No finding
- A finding backed by a PoC that demonstrates a failing test, invariant violation, or reproducible exploit sequence
That is the bar.
Fuck confidence scores
In my opinion, the industry is wasting effort by normalizing triage as a core layer of AI security products. Triage is a symptom of low confidence output. And low confidence output is exactly what we should be designing away from.
I want AI to be able to actually demonstrate the vulnerability. Do the harness writing, the state exploration, the invariant breaking, so that I can focus on actual security reasoning. Not the other way around. Every time I come back to this topic, this tweet is engraved into my brain.

If AI is involved, it should help build exploits and verify them. The final output should not be an opinion for a human to evaluate. It should be a vulnerability we are already completely sure of because the fuzzer found it and the system can prove it, through either path exploration, or through math in the case of formal verification.
That is the standard I care about.
- Not AI generated suspicions.
- Not AI assisted triage.
- Only verified vulnerabilities.
New Product, New Problems
The irony of fuzzing's effectiveness is that it shifts the bottleneck away from tool capability and onto human expertise. A good fuzz run can technically find every vulnerability reachable through program execution.
It will eventually traverse every path the program can take. Trail of Bits states that writing good invariants is "80% of the work", the fuzzer itself is secondary. Test harnesses for complex DeFi protocols are often larger than the protocol code being tested.
This is exactly why a system that automates harness writing and invariant generation is genuinely valuable. I am not going to list all the problems AI can solve here, but this is one area where I believe real progress is possible.
In my experience, LLMs are good at finding candidate invariants. The goal in a smart contract audit often comes down to something simple:
Can we steal the pool's money? Can we steal other people's money?
The target is easy to identify statically. When you reverse engineer a binary, whether an application or a game, the goal one is often trying to reach, is usually straightforward: make the health variable hit 9999999, or inflate your in-game currency.
Statically it is easy to locate where the variable is defined, where it is loaded into memory, and all its cross references.
What is hard is actually weaponizing and manipulating that value at runtime. Smart contracts are the same. The goal is clear, drain the vault but the path to getting there is anything but readable.
This human bottleneck is exactly where LLMs have their most productive role, not scanning for bugs, but statically looking through heaps of lines of code, and finding important properties that should hold up in production, and should be fed into deterministic fuzzing engines.
What I Built
My system is a fully autonomous fuzzing architecture. Given a protocol, it builds a semantic model of the codebase, detects invariants worth testing, pulls live on-chain state, and creates forks so it can interact with the protocol directly and begin to understand its inner workings.
A separate component derives those invariants, writes the fuzz harness, and uploads it to my fuzzing sandbox infrastructure. Most importantly: no human in the loop between ingestion and output. The system is binary, as I want.
Either a vulnerability exists that can violate the invariant, or it does not.
Am I still exposed to hallucination for a model in the harness generation step? Yes, but very minimally. But the key difference is that the output is always grounded in execution. I want everything to be grounded in execution. A failing invariant is not an opinion, it is a reproducible fact.
In my ideal audit flow, I dream of a tool that can fully "one-shot" a protocol end-to-end, taking everything into account and returning a verdict bound in execution.
LLMs are prediction models, producing the next token with some probability of being correct. I do not want probability. I want a verifiable yes or no. Maybe that is just my zero-knowledge personality shining through, make proofs of everything, verify everything.
Results
This has been a long running project, and over the last year it has produced real world results. Backtesting against protocols I had already privately audited has turned out successful. Running it against audit competitions and bug bounty programs has also returned results over the last several months, which is always satisfying to see.
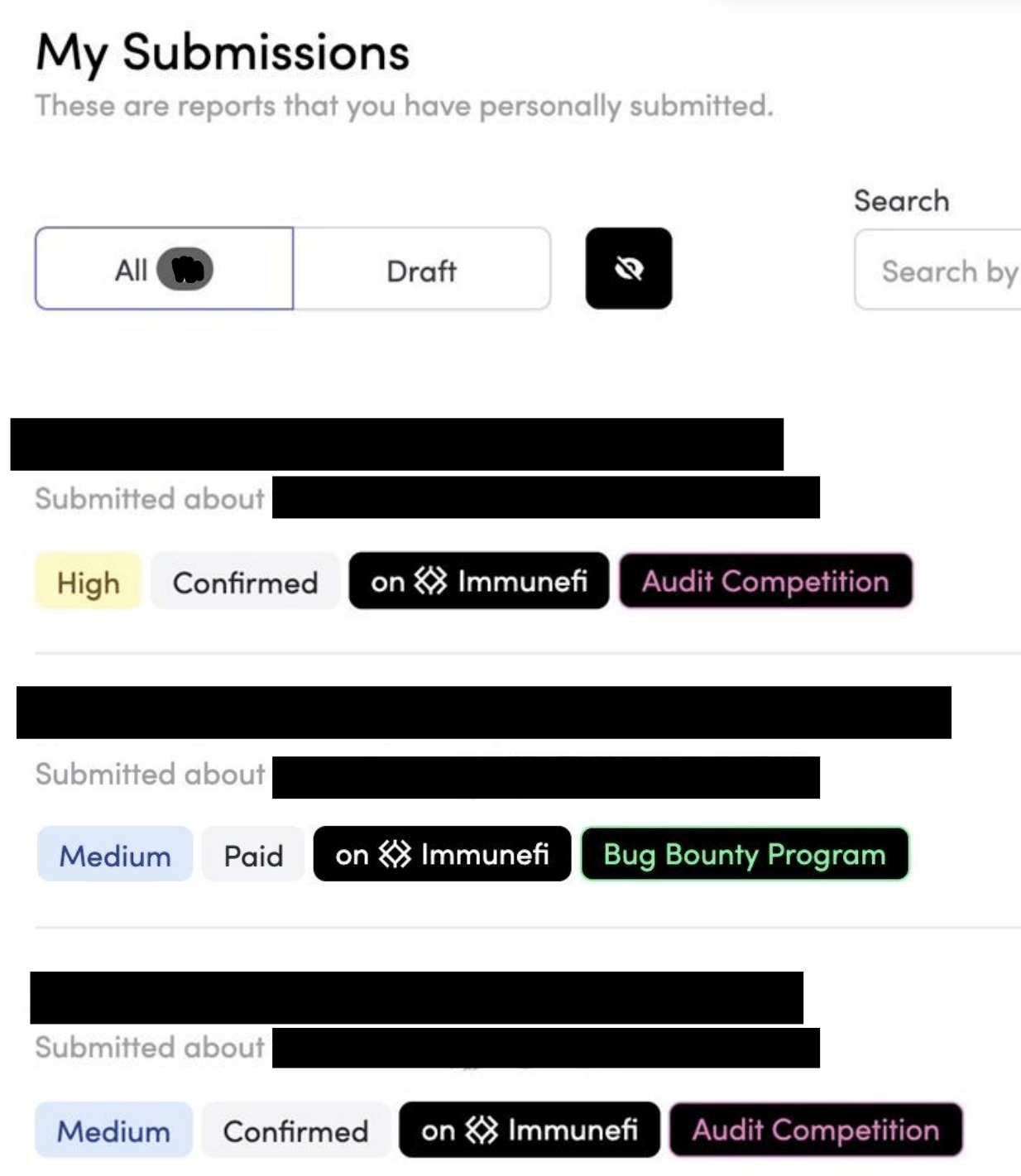
The main downside is the cost of tokens and compute. But when you compare that against the cost of a human audit engagement, the efficiency gains are significant. And compared to other AI audit platforms, a binary system with a 1:1 verifiable vulnerability, one I can hand directly to partners or wardens on audit platforms, already meeting their PoC standards is far more valuable to me than a prioritized ranked list of suspicions and thoughts.
The other advantage is control. I know exactly how many tokens I am burning and on what, rather than paying a dynamically priced product that loads context I do not need and still fails to catch simple bugs a junior auditor would flag.
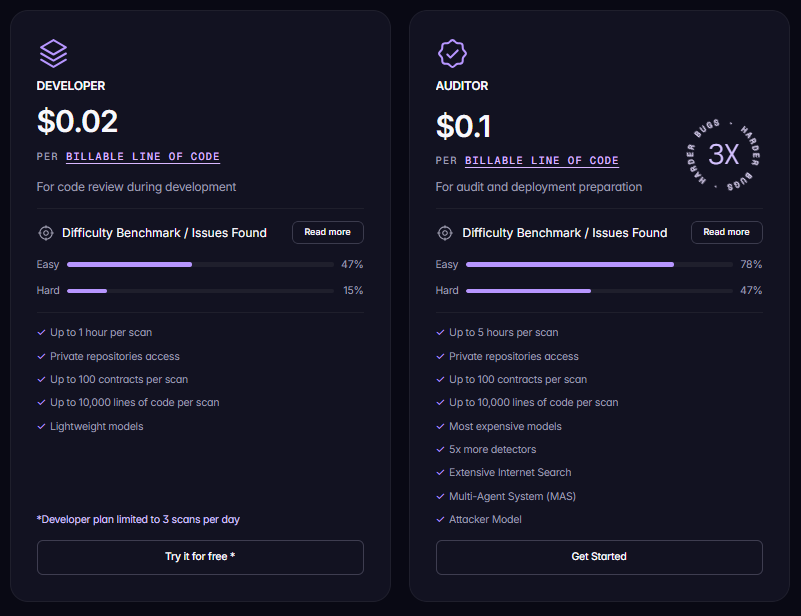
Stop Playing the LLM Lottery!
My broader goal is to propose a fundamentally different angle of attack on smart contract security.
When we care so deeply about verifiability at the protocol level, at the cryptographic level, why do we then turn around and burn tokens hoping to win the LLM lottery?
Spinning up agents, each exploring a different path, each producing confident sounding text, and hoping one of them happens to land on the right vulnerability. That is a lottery. And the odds are not published anywhere.
Others are welcome to build "skill files" and score confidence levels and orchestrate agent outputs. I think that energy is largely wasted.
We are gambling on a black box that a developer built, without knowing whether a bug even exists inside it. That has always been the nature of vulnerability research.
We are always guessing at a target we cannot fully see. But the difference between guessing with a fuzzer and guessing with an LLM is that the fuzzer's guess is executable. When it finds something, we already have the proof.
The future of AI in smart contract security is not a fully autonomous "AI auditor" that outputs a list of possible vulnerabilities for a human to sort through and validate.
I think it is a system that explores every reachable execution path and returns findings we can validate with *near perfect confidence, findings that come with a reproducible exploit by default.
Observant readers will notice that the end state I am describing boils down to verifiability. And yes, formal verification is the logical horizon here, and I am working on that.
But in the meantime, coverage guided fuzzing with AI assisted invariant generation is the most honest path forward I have found.
The house always wins. Learn to count cards.
